
Conference Papers

OATS: Outlier-Aware Pruning Through Sparse and Low Rank Decomposition
Stephen Zhang, Vardan Papyan
International Conference on Learning Representations (ICLR), 2025
arXiv · GitHub
Mini Abstract: We present OATS, a novel approach to model compression by approximating each weight matrix as the sum of a sparse matrix and a low-rank matrix. Without retraining, OATS achieves state-of-the-art performance when compressing large language models.
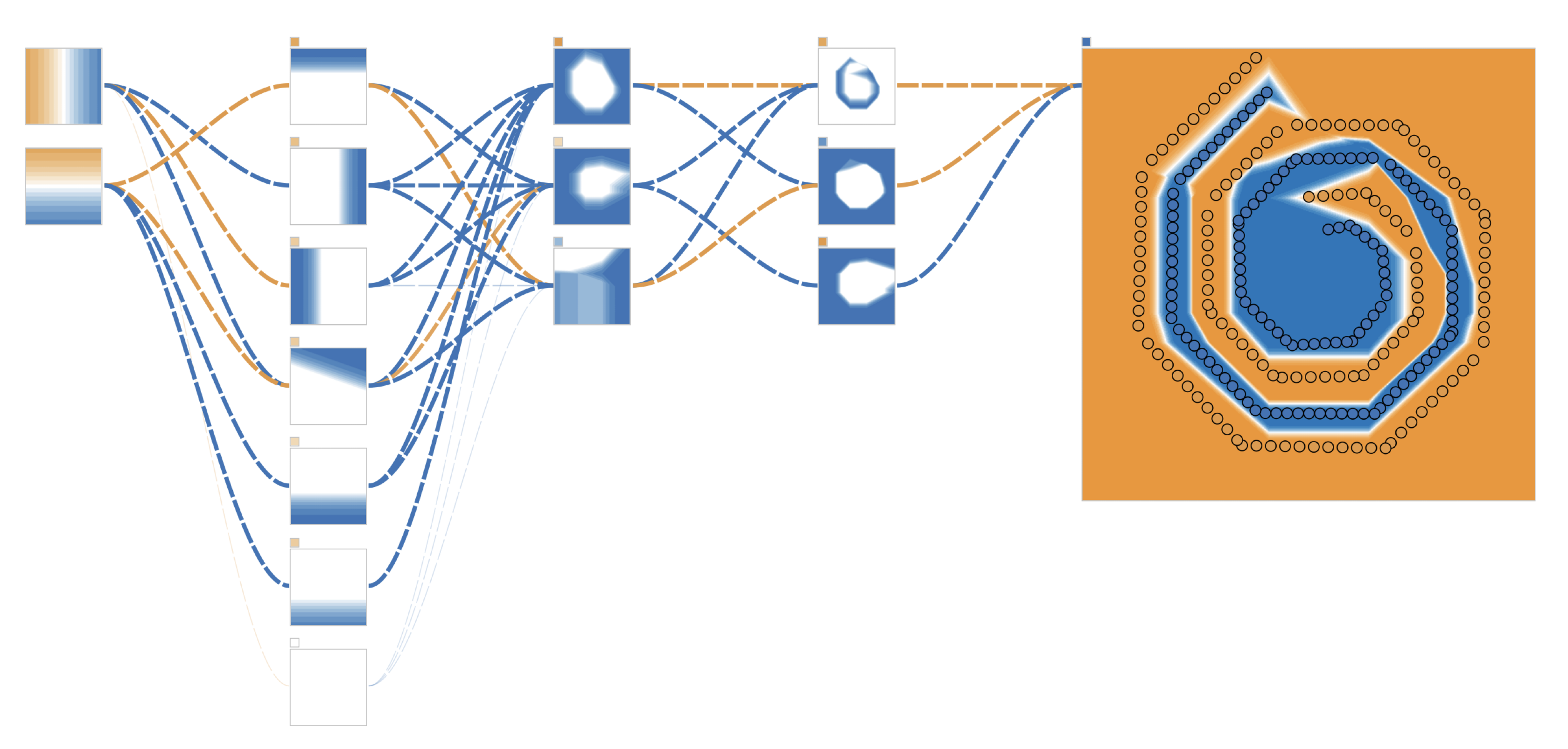
Sparsest Models Elude Pruning
Stephen Zhang, Vardan Papyan
International Conference on Machine Learning (ICML), 2024
arXiv · GitHub
Mini Abstract: We conduct an extensive series of 485,838 experiments, applying a range of state-of-the-art pruning algorithms, and find that there exists a significant gap in performance compared to ideal sparse networks, which we identified through a novel combinatorial search algorithm.
Workshop Papers
![]()
Low-Rank is Required for Pruning LLMs
Stephen Zhang, Vardan Papyan
ICLR Workshop on Sparsity in LLMs (SLLM), 2025
OpenReview
Mini Abstract: We show that pruning is unable to preserve a low-rank structure in the model’s weights, which is crucial for maintaining attention sinks and necessary for model performance.
Preprints
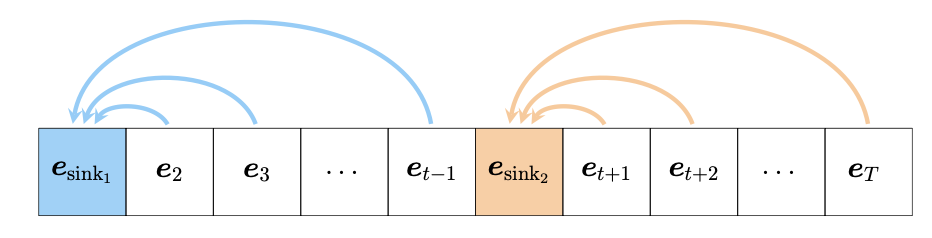
A ‘Catch, Tag, and Release’ Mechanism for Embeddings
Stephen Zhang, Mustafa Khan, Vardan Papyan
Preprint
arXiv
Mini Abstract: We demonstrate that attention sinks utilize outlier features to: catch a sequence of tokens, tag the captured tokens by applying a common perturbation, and then release the tokens back into the residual stream, where the tagged tokens are eventually retrieved.